Atlas vs Anytype (2026): An In-Depth Research Comparison
Atlas is a visual research workspace, Anytype is a local-first PKM tool. Compare paper deconstruction, citation grounding, and compounding context for research.
- Byline

Summary
Use Atlas for cited research work. Use Anytype for private local notes and typed objects.
In this 2026 comparison, Atlas has Knowledge Maps and cited reasoning. Anytype has local encryption, offline access, and typed objects.
Atlas shows why a source backs a claim. Anytype focuses on ownership, objects, and offline use.
Researchers can keep Anytype for private notes and use Atlas for source work.

Upload your papers and get cited answers in Atlas
Use Atlas when your research requires auditable claim-source-justification traces across multiple papers—not just local ownership of notes
Note: We make Atlas. Our team wrote this comparison. Where Anytype is the better fit, we say so plainly. See the table rows where Anytype wins and the "When to choose Anytype" section below. Use this guide to choose the right tool for the work in front of you.
Atlas is a visual research workspace for people who need to understand a body of papers. Think thesis work, treatment decisions, major-purchase research, or a literature review. Anytype is a local-first PKM app. It gives you typed objects for notes, ideas, people, and books, with encryption, peer-to-peer sync, and full data ownership.
The wedge is what happens after the first answer. Atlas turns each paper into a Knowledge Map and each project into a Semantic Map. Every answer links a claim to a source and says why the source backs it. Atlas also compounds prior work in a graph that gets more useful over time. Anytype's privacy and ownership model is strong. If that is your hard rule, Anytype wins. If you need visual maps, cited answers, and a research graph you can defend later, Atlas earns the comparison.
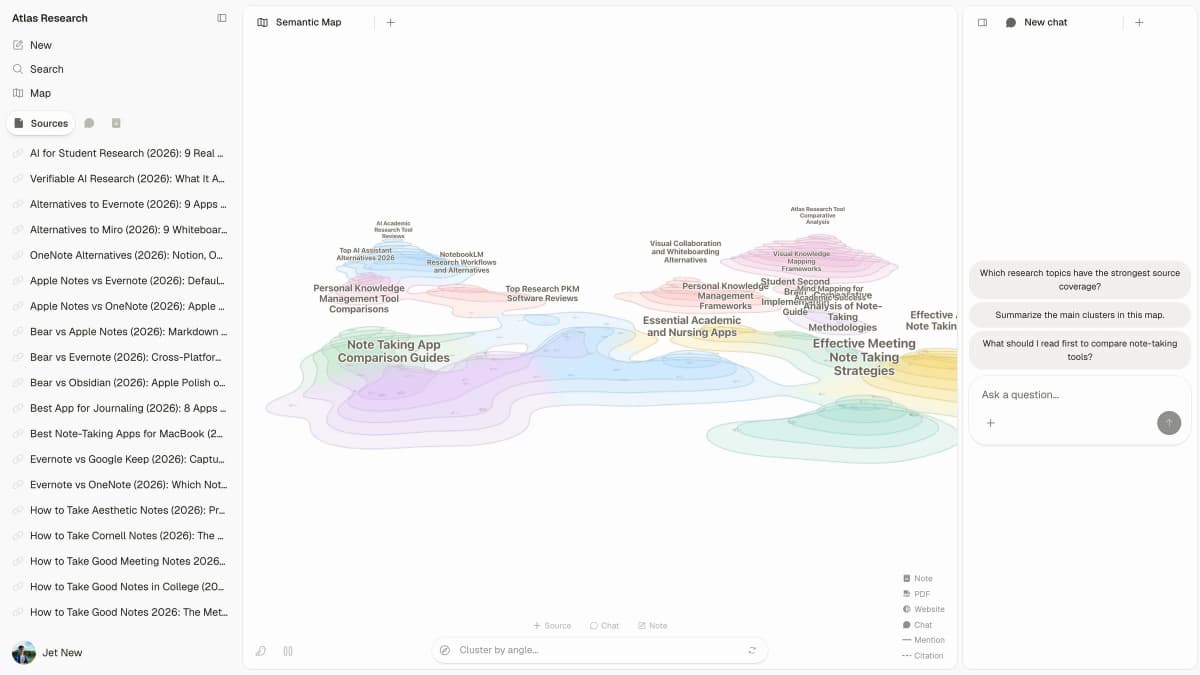
First-party Atlas product screenshot showing the paper view, cited chat, and visual research context.
First-party Anytype product image from the official Anytype homepage, showing the object-based editor surface.
Comparison criteria
The comparison covers six areas: source links, Knowledge Maps, privacy, typed objects, offline access, and export. Anytype wins when local control and flexible objects matter most. Atlas wins when the work depends on cited synthesis across papers.
Atlas vs Anytype comparison table
The table below is the proof surface for this comparison. It covers the six criteria above.
| Atlas | Anytype |
|---|---|
| Citation grounding: claim-source-justification explains why a passage supports a claim | Citation grounding: source links or manual citations, depending on setup |
| Knowledge Maps: deconstructs each paper into claims and evidence ✓ | Knowledge Maps: manual paper objects and notes |
| Privacy model: cloud workspace with private account data, not local-first ✗ | Privacy model: local-first, end-to-end encrypted, peer-to-peer sync ✓ |
| Typed objects: sources, projects, chats, maps, and notes | Typed objects: flexible object types, relations, sets, and collections ✓ |
| Offline access: cloud surfaces need a live connection ✗ | Offline access: local-first workspace works offline ✓ |
| Migration: markdown notes and PDFs import as sources | Migration: markdown and JSON export from Anytype |
Table 1: Atlas vs Anytype feature checklist for source links, maps, privacy, objects, offline use, and export.
How is Atlas different?
Anytype and Atlas both help with reading and reasoning over sources. They diverge on three points that decide whether the output is easy to defend later.
1. Visual maps of every paper and project
Atlas builds two maps as you read. A Knowledge Map turns one paper into claims, proof, terms, and labeled links. You see the paper's spine first, then open the source passages with a click. A Semantic Map turns the whole project into a canvas of sources, notes, chats, and citations. Related items cluster by topic. You can view the same corpus from a new angle without rereading it.
"It's like an ultimate GPT. I can finally see what I've read." Kyle Lao, CEO & Co-founder of MenSC Labs
Anytype does not have per-paper claim-evidence maps or new-angle views across a project. If you have tried to recover a paper weeks later, the Knowledge Map is the first payoff. Visual maps make a body of papers clear at a glance, and the Knowledge Map is the surface Atlas is built around.
2. Every claim traces to a source, and Atlas explains why the source supports it
The hallucination problem in AI research tools is often citation misuse. The model may put a citation next to a claim that the cited passage does not justify. Atlas renders every answer as a claim-source-justification triple. You see the claim, the passage, and why the passage supports the claim. You can click into the source paragraph and read the highlighted lines.
The benchmark Atlas runs internally is the H/V ratio. It checks how often a generated sentence fails a passage-level citation check. Atlas targets H/V < 0.1 on the citation-grounding benchmark. We publish the method in Verifiable AI Research (2026): What It Actually Means. Anytype's answers may include citations or links, but they are not grounded at the claim-justification level. For casual Q&A, that gap may not matter. For a thesis sentence, a brief paragraph, or a treatment summary, it does. Every claim traces to its source, and Atlas explains why the source justifies it.
3. Your projects compound: the second month is 10× the first
Anytype treats each session, project, or workspace as a separate container. Work goes in, an answer comes out, and the next session starts fresh. Atlas builds a persistent per-user knowledge graph across projects. Citations, mentions, Knowledge Maps, and Semantic Maps all accumulate. Open a related project later and Atlas can pull in the right sources, notes, and chat history without re-ingesting them.
This is the capability long-term users mention most. The second month is 10× the first because the graph has something to work with. John Tan, a postdoc using Atlas for a multi-year literature review, describes it as "the only tool where the work I did last semester is still doing work for me this semester." Put plainly: projects get smarter the longer you use Atlas. Anytype does not have the same compounding graph across projects.
Comparing Atlas and Anytype
Both tools touch a researcher's daily work, but they live in different lanes. Atlas is for paper maps, project views, cited AI answers, and reuse across a corpus. Anytype is for typed objects, private notes, and peer-to-peer sync. Anytype is broader on privacy and local ownership. Atlas is deeper at the citation surface. The sections below compare paper structure, project view, cited answers, paper notes, and reuse. Each table includes at least one row where Anytype wins or ties.
Paper deconstruction (Knowledge Map)
The Knowledge Map is Atlas's per-paper view. It turns a paper into claims, evidence, and labeled links. Node text is drawn faithfully from the paper's own language. Breadcrumbs let you move from the high-level thesis to a specific paragraph.
| Atlas | Anytype |
|---|---|
| Multi-level argument structure ✓ | Typed objects per paper with manual relations |
| Labeled relations (motivates, causes, enables) ✓ | ✗ |
| Faithful-to-source node text ✓ | ✗ |
| Hierarchical breadcrumbs ✓ | ✗ |
| ✗ | Local-first typed-object notes ✓. Anytype stores and organizes. Atlas deconstructs arguments |
Table 2: Atlas vs Anytype on paper maps, argument structure, and typed-object notes.
Good to know: The bottom row belongs to Anytype. Atlas does not ship that surface. The Knowledge Map helps when you need a paper's argument weeks after you first read it. Topic chips alone are no longer enough.
Project / corpus view (Semantic Map)
The Semantic Map is Atlas's per-project view. It places sources, notes, chats, and citations on one canvas. Related items cluster by topic. You can view the same canvas under a new topic angle without re-ingesting anything.
| Atlas | Anytype |
|---|---|
| Spatial embedding of sources + notes + chats ✓ | Object graph + sets + collections |
| Auto-labeled topic clusters ✓ | ✗ |
| Topic-angle re-projection ✓ | ✗ |
| Cross-project view ✓ | ✗ |
| ✗ | End-to-end encryption + P2P sync ✓. Anytype leads on privacy. Atlas leads on research depth |
Table 3: Atlas vs Anytype on project maps, topic clusters, and encrypted object graphs.
Good to know: Anytype's strength on that row is genuine. If your work depends on it, that is the boundary. The Semantic Map helps when 200 papers stop being a folder and start being a corpus. You can view the same papers from different angles without rereading.
Citation-grounded answers
Atlas produces cited answer triples. You get the claim, the passage, and why the passage supports the claim. You can jump to the source paragraph, read the highlighted lines, and check the logic.
| Atlas | Anytype |
|---|---|
| Cited reasoning triples ✓ | ✗ |
| Reasoning traces (why this passage supports this claim) ✓ | ✗ |
| Jump-to-source with passage highlight ✓ | ✗ |
| H/V ratio < 0.1 benchmark published ✓ | ✗ |
| ✗ | Open-source and self-hostable ✓. Anytype's open license is a real advantage. It has no bearing on citation depth |
Table 4: Atlas vs Anytype on cited answers, H/V ratio checks, and Anytype's open license.
Good to know: Both tools have a citation surface. The wedge is whether the surface explains why a passage justifies a claim, not just which passage was cited. For everyday Q&A the gap is invisible. For a thesis sentence or a brief paragraph, it is the whole game.
Literature-grounded annotations
Atlas marks up each paper on ingest. Citations inside the paper become first-class objects. When the cited source is open access, Atlas pulls in the relevant passage. You can then see how the paper builds its case across sources without leaving the document.
| Atlas | Anytype |
|---|---|
| Auto-annotate on ingest ✓ | Manual notes on typed objects |
| Multi-citation synthesis (how citations build the argument) ✓ | ✗ |
| Resolve cited sources (open-access) ✓ | ✗ |
| Exact passage / page / paragraph anchors ✓ | ✗ |
| ✗ | Free for personal use ✓. Anytype's free tier is a real pricing advantage. It does not affect the annotation depth |
Table 5: Atlas vs Anytype on paper notes, source markup, and Anytype's free personal tier.
Good to know: Atlas resolves citations inside the paper you are reading. When a paper cites an open-access source, Atlas pulls in the cited passage. The feature shows how one paper builds its case from the sources it cites.
Compounding context across projects
Atlas builds a four-layer graph across your projects. Citations, mentions, Knowledge Maps, and Semantic Maps from one project become context for the next.
| Atlas | Anytype |
|---|---|
| Persistent per-user knowledge graph ✓ | Persistent object graph |
| Citations + mentions + KMs + SMs accumulate ✓ | ✗ |
| Chat history reusable across projects ✓ | ✗ |
| Cross-project source reuse ✓ | ✗ |
| ✗ | Full data ownership ✓. Anytype gives you full control of your data vault. That does not extend to cross-source reasoning |
Table 6: Atlas vs Anytype on reuse across projects and full data ownership.
Good to know: Compounding is hard to show in a short demo. It pays off in week eight. If your work is many small projects, Anytype's separate-session model is the right choice. Isolation is a design choice, and for some workflows it is the correct one.
Price comparison
Atlas is a paid product. There is no perpetual no-cost plan. The free sample gives you 10 sources and 5 lifetime AI chats. After that, Atlas Pro is $20/mo or $204/yr. At the paid tier, Atlas is the only tool here with Knowledge Map, Semantic Map, cited answers, and a graph that compounds. You are not paying for chat tokens alone. You are paying for research surfaces that Anytype does not have at any tier.
| Atlas | Anytype |
|---|---|
| Free: ✗ (evaluation sample only: 10 sources · 5 lifetime AI chats) | Free: Free for personal use, open-source ✓ |
| Pro: $20/mo or $204/yr (1,000 sources · 1,000 chats/month · all features) | Paid: Network plans for storage and team use (pricing varies) |
| Pro unlocks Knowledge Map, Semantic Map, cited reasoning, compounding graph ✓ | ✗ |
Table 7: Atlas vs Anytype pricing for Atlas Pro, Anytype's free tier, and paid network plans.
If that paper-map workflow is the Atlas side you need, sign up for an evaluation sample. You get 10 sources and 5 lifetime AI chats, enough to upload one paper and test the Knowledge Map on your own source.
When to choose Atlas vs Anytype
- Want paper structure deconstructed multi-level? Go with Atlas. (Knowledge Map)
- Want answers that explain how each citation justifies the claim? Go with Atlas. (cited reasoning)
- Want your projects to compound over months? Go with Atlas. (4-layer graph)
- Want encrypted local notes with full data ownership? Go with Anytype.
- Want open-source, privacy-first PKM? Go with Anytype.
- Tied: typed-object paper database with full local control. Both work, with different priorities. The wedge only opens once you build a corpus you'll return to.
Recommendations by user type
- PhD researchers: Atlas. In years 1–2, the Knowledge Map helps you recover each paper without rereading it. In thesis years, cited reasoning keeps each thesis sentence anchored to a passage. Anytype works for one-off tasks. The multi-year graph is what makes Atlas the right tool here.
- Students doing literature reviews and thesis research: Atlas, scoped to dissertation, thesis, and literature review work. The Knowledge Map saves the most time in the lit-review phase. The graph keeps prior work reachable across semesters.
- Knowledge workers (consultants, analysts, PMs, journalists): Atlas when you read reports and papers for client work. Use Anytype for adjacent jobs it handles well. The citation trail is the difference between a slide you can defend in a meeting and a slide you cannot.
- High-stakes personal research: Atlas when cited reasoning and a research graph matter. Anytype when encryption and full data ownership are must-haves.
Anytype is strongest when the workspace itself is the product. It gives you private objects, local storage, and a system you tune over time. Atlas is stronger when the recurring job is reading sources, recovering arguments, and defending a synthesis months later. The practical test is whether the same papers will keep mattering across projects. If they will, the Atlas graph and citation trail save repeated setup. If not, Anytype's self-contained workspace is lighter.
Migrating from Anytype to Atlas
Anytype's data model is built around typed objects. Its pages are blocks, and you can add custom object types, relations, and sets/collections. Storage is local-first. Data lives in an encrypted vault on your device and syncs peer-to-peer or through Anytype's network. Export options include markdown and JSON. For a move to Atlas, markdown is the practical path for prose. JSON is useful only when you need relation data as flat fields.
Page bodies migrate cleanly. Notes, ideas, reading notes, and daily logs come across as markdown files. Atlas imports them as text sources. PDFs attached to Anytype objects can be re-uploaded to Atlas. Each PDF becomes a Knowledge Map on ingest. Citations are auto-annotated, and the paper becomes a node in the project's Semantic Map. Tags and simple fields such as author, year, and status survive as flat markdown data.
Custom object types do not migrate as objects. Atlas uses sources, projects, chats, Knowledge Maps, Semantic Maps, and notes. It does not use user-defined object types. Sets and collections do not migrate either. The closest Atlas match is the Semantic Map's topic view. It clusters by meaning rather than by manual filter. Custom relations become flat fields instead of links. End-to-end encryption and local-only storage do not carry over because Atlas runs in the cloud.
Export your Anytype workspace as markdown and ZIP. Pull out the PDFs first. Upload them to Atlas in batches of 10–20 so Knowledge Maps can run while you keep working. Import markdown notes as text sources grouped by project. Build one Atlas project per Anytype workspace or major topic. Merging everything into a single project makes the Semantic Map harder to read. Once the corpus is in, run a Semantic Map and one synthesis chat per project. Keep the Anytype vault as a cold archive for anything that does not need cited reasoning or Knowledge Maps.
A worked example: building a literature review section
Here is the walkthrough. You are writing a review section on RAG for science Q&A. You have 18 papers and need about 800 words with citations you can defend.
In Atlas, upload the 18 PDFs to a new project. Each paper becomes a Knowledge Map on ingest. Within a few minutes, you can open a paper and see its thesis, claims, proof, terms, and labeled links. You do not need to reread each paper end to end. Read the Knowledge Map, then open the source paragraph only when you need exact words. Next, open the Semantic Map. The 18 papers cluster by topic, such as retrieval method, benchmark, error rate, and domain. Re-project the map around "what each paper claims about citation grounding" to get the angle for your section.
Then ask a synthesis chat what the papers agree on and where they differ. The answer comes back as cited reasoning triples. Each claim has the passage it draws from and why the passage supports it. You click into the source paragraph, check the highlighted lines, and drag the triple into your draft. The 800 words assemble in roughly two sittings instead of a week.
In Anytype, you create a Book or Paper object type if you have not already. You add 18 objects, attach the PDFs as file blocks, and type reading notes into each body. To synthesize, you hand-link related objects with relations or backlinks. You build a tag-filtered set and read your notes back to find the threads. The PDFs are stored, but the reading and synthesis are yours to do. There is no Knowledge Map of each paper's argument. There is no Semantic Map clustering the 18 papers by topic angle. There is no cited reasoning surface that explains why a passage supports a specific claim. You can be rigorous in Anytype, but the rigor comes from your manual links.
Anytype is stronger when the 18 PDFs are sensitive. Think clinical notes, legal drafts, or unpublished collaborator work. Its local-first encrypted storage keeps them off a central cloud by design. It is also stronger when you want Book, Author, Lab, and Funding Source as first-class typed objects with custom relations. Anytype is a real PKM tool for daily notes, journals, and databases in a way Atlas is not. The trade is depth for research work against breadth for a private database. Pick the side that matches the work in front of you.
When Anytype is the right call
There are research and PKM jobs where Anytype is the right tool. Four cases are clear.
Choose Anytype for local-first or offline-first work. If your laptop is often offline, Anytype is built for that. This covers fieldwork, travel, and secure sites. Atlas requires a live link to the cloud surfaces.
Choose Anytype for an encrypted vault. If the corpus contains sensitive material, Anytype's end-to-end encryption is the better fit. Health notes, legal drafts, private journals, and unpublished manuscripts belong here. Atlas encrypts at rest and in transit, but it is not client-side encrypted. For a hard client-side privacy rule, Anytype wins outright.
Choose Anytype for flexible custom data models. If you want typed objects for Books, People, Labs, Funding Sources, Daily Logs, or Habits, Anytype is more expressive. Atlas is built around sources, projects, chats, maps, and notes. It is built for research. Anytype is built for flexibility.
Choose Anytype for sync without a central cloud copy. Its peer-to-peer sync keeps your phone, laptop, and tablet in sync. If you want devices in sync but the data never centralized, that is Anytype's lane.
If any of these four are must-haves, choose Anytype. Atlas starts to matter when the work is deep research on a corpus you'll return to. It is not the fit for generic PKM with strict privacy.
Common objections and edge cases
"I already have hundreds of objects in Anytype, is the migration cost worth it?" Probably not for daily notes, journals, or contact records. Move only the research corpus. That means the PDFs and the reading notes that go with them. Keep Anytype as the home for everything else and use Atlas for the research surfaces. Many long-term users run both. The move is bounded if you scope it to the corpus that benefits from Knowledge Maps and cited reasoning.
"What about citation export back out of Atlas?" Atlas exports citations and synthesis chats as markdown with cited reasoning blocks preserved inline. You can paste a section into a draft in any editor, including Anytype, and keep the reasoning attached. Knowledge Maps are Atlas-native and stay in Atlas's schema. The prose, citations, and source files all travel. If Anytype is your long-term archive, the export round trip is workable.
"Does Atlas work if I want full data ownership the way Anytype offers it?" No, and we will not pretend otherwise. Atlas runs in the cloud. Your sources and chats are private to your account, but they are not stored client-side or end-to-end encrypted. If you want the Anytype posture, choose Anytype. You get an open-source client, peer-to-peer sync, and a local vault you control. Atlas's bet is narrower. For deep research, the cloud surface earns the trade for a specific kind of work. It is not a universal claim.
Final comparison workflow
If the Atlas side is the better fit for your research job, upload your papers and get cited answers in Atlas. Use the evaluation sample on one real paper first. The test is simple: run a Knowledge Map, ask one cited question, and check whether the source trail is worth the cloud trade-off.
Upload your papers and get cited answers in Atlas
Use Atlas when your research requires auditable claim-source-justification traces across multiple papers—not just local ownership of notes
Frequently Asked Questions
Yes. That is the core of Atlas's citation surface. Every answer is rendered as a claim-source-justification triple: the claim, the passage it draws from, and a one-sentence explanation of why the passage supports the claim. You can click into the source paragraph and read the highlighted sentences in context. Anytype may cite at the sentence level or link to sources, but it does not render the reasoning trace that connects the claim to the passage. That trace is the move when you need to defend a thesis sentence, a brief paragraph, or a treatment-plan summary. Read more about how Atlas grounds claims in Verifiable AI Research (2026): What It Actually Means.