Atlas vs Capacities (2026): An In-Depth Research Comparison
Atlas is a visual research workspace; Capacities is an object-based note app. Compare paper deconstruction, cited answers, research context, and tool fit.
- Byline

Summary
As of 2026, use Atlas for citation-grounded answers and visual Knowledge Maps. Use Capacities for object-based personal knowledge management.
The comparison covers source proof, object structure, Knowledge Maps, migration, privacy, and context reuse.
Atlas explains claim support from passages, while Capacities organizes people, books, notes, and topics as objects.
Capacities can hold everyday PKM while Atlas handles research source sets.

Synthesize your research corpus with cited answers in Atlas
Use Atlas when Capacities holds your PKM substrate but your research sources need claim-source reasoning traces, not just linked object properties
Note: We make Atlas. Our team wrote this comparison. Where Capacities has the better answer for a given job, the article says so plainly. See the table rows where Capacities wins and the "When to choose Capacities" section below. The goal is simple: help you pick the right tool for the work in front of you. Atlas is not the answer to every research job.
Atlas is a visual research workspace for people whose work depends on a body of papers. That may be a thesis, a treatment choice, a purchase teardown, or a literature review. Capacities is an object-based note app for personal knowledge management, or PKM. Instead of pages, you create typed objects: notes, ideas, people, and books. Those objects link to daily notes and a graph view. Both tools touch a researcher's day. The wedge is what happens after the first answer.
Atlas turns each paper into a Knowledge Map, which is a visual map of the paper's claims and evidence. It projects a whole source set into a Semantic Map. It runs answers through claim-source-justification, which means the claim, the source passage, and the reason the passage supports the claim appear together. Atlas also reuses prior work in a graph, so projects get smarter over time. Capacities is the better PKM database. Its typed objects and daily notes are strong when you want more structure than a flat note graph. If you need to trust the answers for a thesis, treatment plan, brief, or hiring call, Atlas earns the comparison.
How we compared Atlas and Capacities
For this 2026 update, we used one rule: start from the job, then ask which tool owns it. Atlas wins when the job is reading, mapping, citing, and reusing a source set. Capacities wins when the job is keeping typed PKM objects across daily notes, people, books, projects, and recurring records.
Feature comparison table
| Atlas | Capacities |
|---|---|
| Citation grounding: claim-source-justification shows the claim, source passage, and why the passage supports the claim. Use Atlas when a sentence must survive source review. | Notes and AI answers can point to linked content, but Capacities is not built around passage-level justification. |
| Knowledge Maps: per-paper maps show claims, evidence, definitions, and labeled links. Use Atlas for deep reading of papers. | Graph and object links show connected records. Capacities does not map a paper's argument structure. |
| Project, source, annotation, chat, Knowledge Map, and Semantic Map are the main units. | Object-based organization: typed objects for people, books, meetings, sources, projects, places, and custom types. Use Capacities for everyday PKM structure. |
| ✗ No custom object type database. Source metadata and project context are available, but Atlas is not built for saved object queries. | Typed properties and queries ✓. Custom fields, object types, collections, and queries make Capacities the better fit when schema is the main value. |
| Upload PDFs and keep markdown notes as project context or sidecars. Migrate one active research project first. | Export markdown or JSON plus attachments from the object workspace. |
| Context reuse: the research graph reuses citations, mentions, maps, chats, and notes across projects. Use Atlas when evidence needs to compound across projects. | The object graph reuses typed records and links inside the PKM workspace. |
Table 1: Atlas proof features beside Capacities object notes.
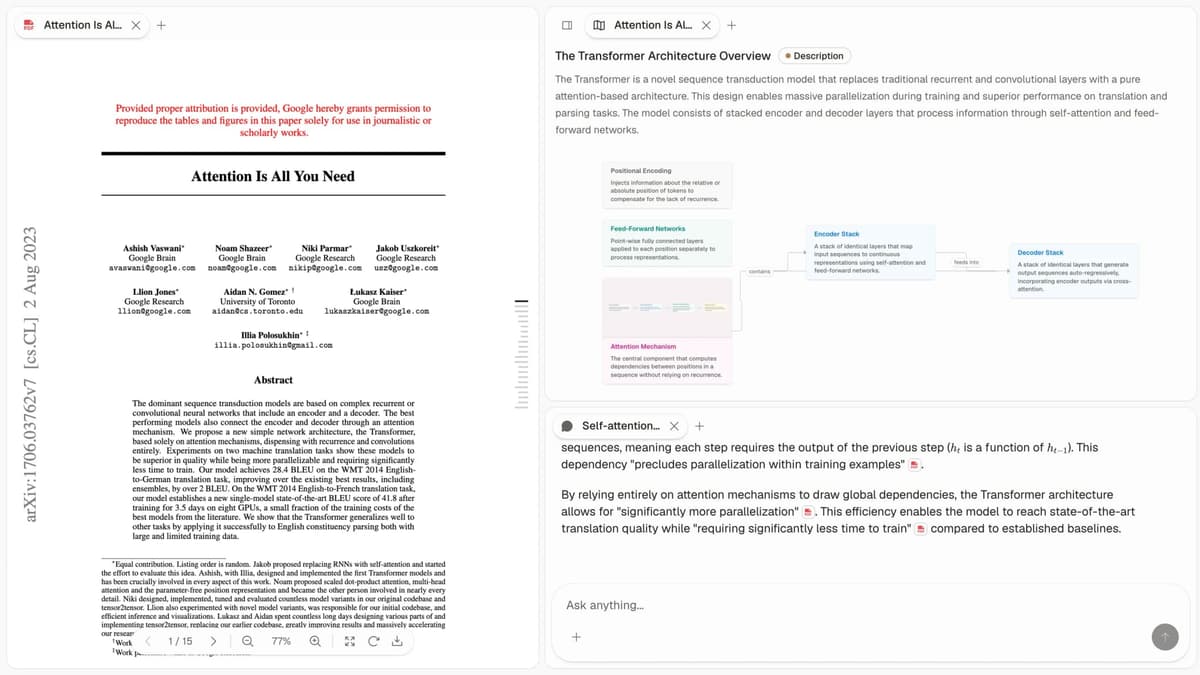
Source: Atlas first-party product screenshot. It shows the visual paper map and citation-tracing surface used throughout this comparison.
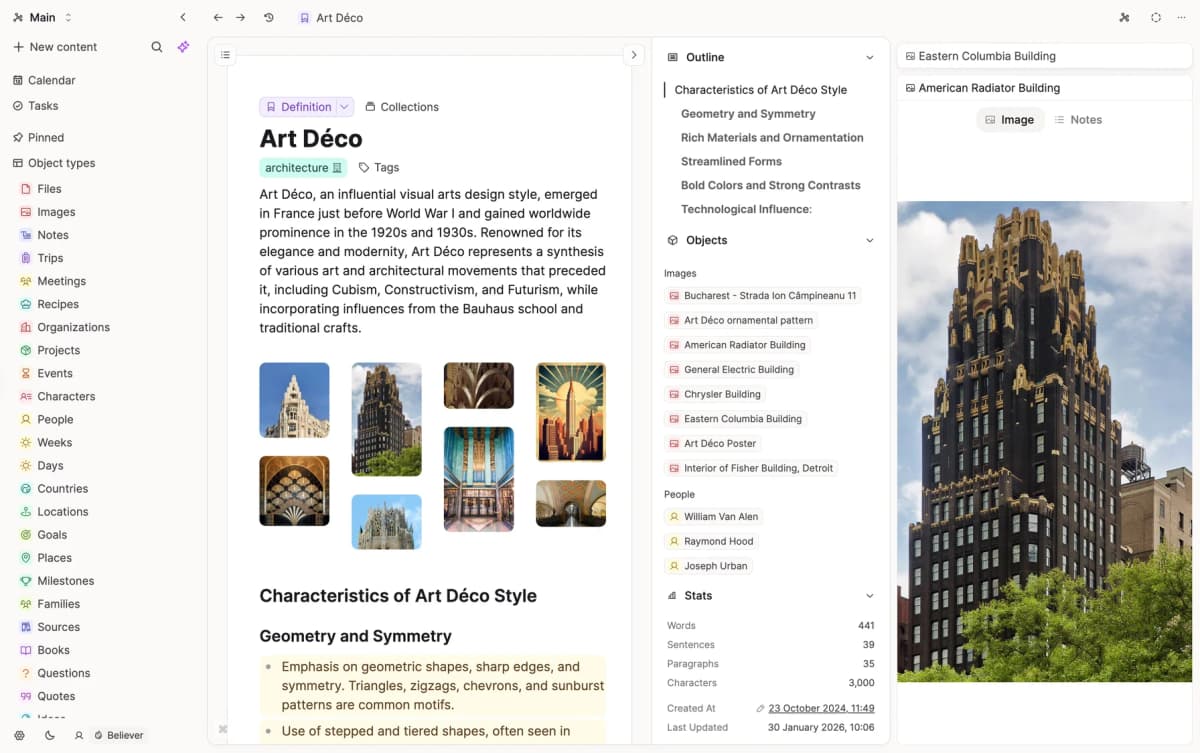
Source: Capacities official product page screenshot. It shows the typed-object workspace this comparison is about.
How is Atlas different?
Capacities and Atlas overlap at the surface. Both help with reading and source work. They split on three points that decide whether the output can be shared and defended. This section walks through the three differences, in order.
1. Visual maps of every paper and project
Atlas builds two kinds of visual map as you read. A Knowledge Map breaks one paper into claims, evidence, definitions, and labeled links between them. You see the paper's spine first. Then you can click down into the passages that support it. A Semantic Map places your whole project on a canvas: sources, notes, chats, and cited passages. Related items cluster by topic. You can view the same canvas through a new topic angle without reading everything again. This is how 200 papers stop being a folder and start being a source set.
"It's like an ultimate GPT. I can finally see what I've read." Kyle Lao, CEO & Co-founder of MenSC Labs
Capacities does not break each paper into claims and evidence. It also does not re-map a whole project by topic angle. If you have spent an afternoon trying to recall a paper from three weeks ago, the Knowledge Map pays off first. Visual maps make a body of papers legible at a glance, and the Knowledge Map is the surface Atlas is built around.
2. Each claim traces to a source, and Atlas explains why the source supports it
The hallucination problem in AI research tools is not just "the model made something up." It is "the model put a source next to a claim that the passage does not prove." Atlas renders each answer as claim proof: the claim, the passage, and a short reason the passage supports the claim. You can click into the source paragraph and read the highlighted lines in context.
Atlas tracks this with the H/V ratio. It measures generated sentences whose citation fails a passage check, divided by those that pass. Atlas targets H/V < 0.1, and we publish the benchmark in the verifiable AI research benchmark. Capacities can cite or link to sources, but the proof surface differs. It reaches sentence-to-citation at best. Atlas goes further by showing the claim, the passage, and the reason the passage supports the claim. For casual Q&A the gap may not matter. For a thesis sentence, legal brief, or treatment note, it does. Every claim traces to its source, and Atlas explains why the source justifies it.
3. Your projects compound: the second month is 10× the first
Capacities treats each session, project, or workspace as its own container. Work goes in, an answer comes out, and the next session starts fresh. Atlas builds a persistent research graph across projects. The graph stores cited passages, mentions, maps, and chats. Open a new project on a related topic and Atlas can pull in useful sources, prior notes, and chat history without another ingest step.
This is the point we hear about most from long-term users. The second month is 10× the first because the graph has something to work with. John Tan, a postdoc using Atlas for a multi-year literature review, describes it as "the only tool where the work I did last semester is still doing work for me this semester." Put plainly: projects get smarter the longer you use Atlas. Capacities does not have an equivalent persistent compounding graph across projects, which is the wedge for sustained, multi-month research.
Comparing Atlas and Capacities
Both tools touch a researcher's day, but they live in different categories. Atlas covers paper maps, project maps, source-cited answers, and context reuse across a source set. Capacities covers typed objects, daily notes, and a graph view. Its object model is broader for general PKM. Atlas goes deeper at the source-proof layer. The next five sections cover paper maps, project maps, cited answers, source annotations, and context reuse. Each table includes at least one row where Capacities wins or ties.
Paper deconstruction comparison (Knowledge Map)
The Knowledge Map is Atlas's per-paper surface. It breaks one paper into a layered claim map. The links show how claims, evidence, and definitions relate. Node text is drawn faithfully from the paper's language. Breadcrumbs let you move from the high-level thesis down to a specific paragraph.
| Atlas | Capacities |
|---|---|
| Multi-level argument structure ✓ | Typed "book" or "paper" objects with manual notes |
| Labeled relations (motivates, causes, enables) ✓ | ✗ |
| Faithful-to-source node text ✓ | ✗ |
| Hierarchical breadcrumbs ✓ | ✗ |
| ✗ | Object-based personal knowledge management substrate (typed objects) ✓. Capacities organizes your PKM substrate. Atlas deconstructs source arguments |
Table 2: Paper map rows beside Capacities object notes.
Good to know: The bottom row belongs to Capacities. Atlas does not ship that surface. The Knowledge Map's payoff is recovering a paper's argument three weeks after you first read it, when topic chips alone are no longer enough.
Try Atlas: Sign up for an evaluation sample (10 sources · 5 lifetime AI chats) and run a Knowledge Map on one of your own papers. Used by researchers at NUS, NTU, SMU, and eight other universities.
Project map (Semantic Map)
The Semantic Map is Atlas's per-project surface. It places sources, notes, chats, and cited passages on a canvas. Related items cluster by topic. You can view the same canvas from another topic angle without ingesting files again.
| Atlas | Capacities |
|---|---|
| Spatial embedding of sources + notes + chats ✓ | Object graph + collections |
| Auto-labeled topic clusters ✓ | ✗ |
| Topic-angle re-projection ✓ | ✗ |
| Cross-project view ✓ | ✗ |
| ✗ | Daily-note workflow integrated with objects ✓. Capacities integrates daily notes with objects. Atlas focuses on citation grounding across sources |
Table 3: Project map rows beside Capacities object links.
Good to know: Capacities's strength on that row is genuine. If your work depends on it, that's the boundary. The Semantic Map pays off when 200 papers stop being a folder. They become a corpus you can view from new topic angles without re-reading.
Source-backed answers
Atlas produces claim proof. Each answer includes the claim, the passage, and a short reason the passage supports the claim. You can jump to the source paragraph, read the highlighted lines, and check whether the reasoning holds.
| Atlas | Capacities |
|---|---|
| Claim-source-justification triples ✓ | ✗ |
| Reasoning traces (why this passage supports this claim) ✓ | ✗ |
| Jump-to-source with passage highlight ✓ | ✗ |
| H/V ratio < 0.1 benchmark published ✓ | ✗ |
| ✗ | Object templates for different content types ✓. Capacities gives you structured templates. Atlas generates reasoning traces from source passages |
Table 4: Cited answer rows beside Capacities note templates.
Good to know: Both tools have a citation surface. The wedge is whether the surface explains why a passage justifies a claim, not just which passage was cited. For everyday Q&A the gap is invisible, but for a thesis sentence or a brief paragraph it's the whole game.
Literature-grounded annotations
Atlas adds source notes when a paper is ingested. Citations inside the paper become first-class objects. When a cited source is open access, Atlas can resolve it and pull the relevant passage. You can see how the paper builds its case across sources without leaving the document.
| Atlas | Capacities |
|---|---|
| Auto-annotate on ingest ✓ | Manual notes on typed objects |
| Multi-citation synthesis (how citations build the argument) ✓ | ✗ |
| Resolve cited sources (open-access) ✓ | ✗ |
| Exact passage / page / paragraph anchors ✓ | ✗ |
| ✗ | Markdown export and database queries ✓. Capacities gives you schema-driven queries. Atlas generates source-cited answers from passages |
Table 5: Source note rows beside Capacities query exports.
Good to know: This feature resolves citations inside the paper you're reading. When a paper cites an open-access source, Atlas pulls in the cited passage. It is not web grounding. It shows how one paper builds its case from the sources it cites.
Context reuse across projects
Atlas builds a graph across all your projects. Cited passages, mentions, maps, chats, and notes from one project can become context for the next.
| Atlas | Capacities |
|---|---|
| Persistent per-user knowledge graph ✓ | Persistent object graph |
| Citations + mentions + KMs + SMs accumulate ✓ | ✗ |
| Chat history reusable across projects ✓ | ✗ |
| Cross-project source reuse ✓ | ✗ |
| ✗ | No-cost plan for solo personal knowledge management use ✓. Capacities has a pricing advantage for solo PKM. It does not cover source-cited answers or Knowledge Maps |
Table 6: Atlas graph reuse beside Capacities object history.
Good to know: Compounding is the slowest capability to demonstrate in a demo and the biggest payoff in week eight. If your work is many small, unrelated projects, Capacities's session-isolated design is the right choice. That isolation is a deliberate design decision. Compounding pays off for sustained, multi-month research.
Price comparison
Atlas is a paid product. There is no perpetual no-cost plan. You get a short evaluation sample (10 sources · 5 lifetime AI chats), and after that you pay $20/mo or $204/yr for Atlas Pro. At the paid tier, Atlas is the only tool with Knowledge Map, Semantic Map, claim-source-justification, and compounding graph. You aren't paying for chat tokens. You're paying for capabilities that Capacities doesn't have at any tier.
| Atlas | Capacities |
|---|---|
| Free: ✗ (evaluation sample only: 10 sources · 5 lifetime AI chats) | Free: No-cost plan: full features for personal use ✓ |
| Pro: $20/mo or $204/yr (1,000 sources · 1,000 chats/month · all features) | Paid: Pro $10/mo, AI features, advanced queries |
| Pro unlocks Knowledge Map, Semantic Map, claim-source-justification, compounding graph ✓ | ✗ |
Table 7: Atlas paid plan beside Capacities free and paid plans.
When to choose Atlas vs Capacities
- Want paper structure deconstructed multi-level? Go with Atlas. (Knowledge Map)
- Want answers that explain how each citation justifies the claim? Go with Atlas. (claim-source-justification)
- Want your projects to compound over months? Go with Atlas. (4-layer graph)
- Want typed objects and daily notes for PKM? Go with Capacities.
- Tied: keeping a typed-object database of papers you have read**: both work fine for different jobs. The wedge only opens up once you're building a corpus you'll return to.
Recommendations by user type
- PhD researchers: Atlas. In years 1-2, the Knowledge Map helps you avoid re-reading each paper. In years 3-4, claim proof helps anchor thesis sentences to passages. Capacities works for one-off tasks. Atlas is stronger for a multi-year source set.
- Students doing literature reviews and thesis research: Atlas, scoped to the thesis or lit-review workflow. The Knowledge Map saves the most time during reading. The graph keeps prior work reachable across terms.
- Knowledge workers (consultants, analysts, PMs, journalists): Atlas when reading and citing papers is the core work. Capacities when typed PKM objects are the daily need.
- Personal researchers with high-stakes questions: Atlas. Use it for medical, legal, major-purchase, or deep self-study research where you need to defend the answer. Capacities is a fine starting tool. Atlas is the tool you graduate to once the source trail matters.
Capacities is built for object-based PKM: people, books, meetings, ideas, and projects connected by typed notes. Atlas is built for source-heavy research where each answer needs a passage trail and each paper benefits from a Knowledge Map. Pick Capacities when the object model is the organizing system. Pick Atlas when the source set is the organizing system and the same evidence will be queried again.
What about Obsidian, Notion, and Anytype?
The broader search results usually bring in three nearby tools: Obsidian, Notion, and Anytype. Each one solves a different version of "connected knowledge." None is a one-for-one Capacities swap inside this article.
Obsidian is the strongest pick when you want local markdown files, links, backlinks, plugins, and graph views. It is closer to a personal knowledge base than to Atlas. Choose it if file ownership and a local note graph matter more than typed objects or citation-grounded research answers.
Notion is the strongest pick when the workspace is shared with a team. Docs, wikis, projects, and databases sit in one place. Notion AI works across that shared space. It can hold research notes, but its center of gravity is team knowledge management. Passage-level proof for a paper corpus is a different job.
Anytype is the closest neighbor to Capacities in this group because it also uses objects, templates, graph/database views, and a local-first posture. Choose Anytype when ownership, privacy, and object structure are the deciding constraints. Choose Capacities when its object experience and daily-note workflow fit your PKM habits better. Choose Atlas when the question is not "where should my objects live?" but "can I defend this research claim from the source passage?"
Migrating from Capacities to Atlas
Capacities organizes work around typed objects. A "paper" object can hold authors, year, journal, custom fields, linked authors, linked tags, and markdown notes. Daily notes link back to those objects. Queries can surface objects that match a filter. It is a clean model. When you move to Atlas, the practical question is what survives.
Start with Capacities's markdown export. Open the collection you want to move (for a literature review this is usually the "Paper" collection plus any "Author" and "Tag" collections referenced by it), export to markdown, and you get one .md file per object with frontmatter for the properties and a body for the notes. The PDFs you attached to each Capacities object export alongside the markdown when you include attachments in the export.
The source files and the markdown body of your notes migrate cleanly. That includes PDFs, EPUBs, and web captures. Upload the PDFs to a new Atlas project and they become Knowledge Maps on ingest. Your manual notes from Capacities can be pasted into Atlas as project notes. You can also keep them as markdown sidecars if you want the original prose.
What does not migrate as a native concept: custom object types, typed links between objects, and saved property queries. Atlas's main unit is the project. A "Paper" object becomes a source inside a project. Linked "Author" and "Method" objects become notes or tags. They do not carry over as typed records. If your setup depends on multi-hop queries such as "show me all papers by authors who cite this method," Atlas does not replace that surface. The Semantic Map and the research graph solve a different job.
A practical migration approach is to move one active project first. Start with 10 to 30 sources. Let Atlas generate Knowledge Maps. Run a few cited chats and compare the source trail. Then decide whether the rest of the corpus belongs there. Many users keep Capacities for daily notes and general PKM. They move only the paper-heavy projects to Atlas. That is the lower-risk path if you have years of object history you do not want to disturb.
A worked example: writing a literature-review section
Suppose you are writing a related-work section on RAG. You have 18 papers. They cover sparse search, dense search, hybrid methods, and recent end-to-end systems. Here is how the work feels in Atlas versus Capacities.
In Atlas, you create a project and drop the 18 PDFs in. Each paper gets a Knowledge Map. Claims appear as nodes. Evidence appears as support. Links show how the pieces relate. Atlas keeps node text anchored to the paper's own language. You open the map for the foundational DPR paper and see the spine of the argument. Drop two levels and you are reading the passage that defines the in-batch negatives sampling trick. You do the same for the other 17 papers in maybe 20 minutes because you are moving through arguments instead of re-reading.
Then you open the Semantic Map for the project. The 18 papers cluster by topic automatically. Sparse search groups on one side, dense search in the middle, hybrid and end-to-end on the other. You switch to the angle "training-data strategy." The same 18 papers now cluster by how each one builds its training set. That second view turns 18 PDFs into a corpus you can reason over.
Now the writing. You ask Atlas which three approaches to out-of-domain queries are most defensible across these papers. The answer comes back as claim proof. Each claim has the source passage attached and a short reason why the passage supports it. You click into the third claim, read the highlighted sentences in the source paragraph, and decide whether to keep, rewrite, or discard the sentence. Drafting the section is now a matter of stitching the verified claims together, with the citations already attached.
The Capacities flow is different. You create a "Paper" object for each PDF. You paste the abstract and a few notes. You link each paper to "Method" and "Author" objects, then tag the relevant ones. To draft the related-work section, you scroll through your manual notes. You hand-pick useful lines. Then you write the prose and place citations from memory or by checking the source object. Capacities stores the paper as an object. The argument structure still has to be recovered from the PDF when you write. The linking is hand-typed, and the source proof is whatever discipline you bring to it. For 18 papers it is workable. For 80 it is the bottleneck.
When Capacities is the right call
Capacities is a good fit for several jobs Atlas does not do. If each day links to people you met, books you started, ideas you had, and tasks you opened, Capacities is strong. Its daily note plus typed-object model is clean. Atlas does not have a daily-note surface and does not try to be a PKM database.
A personal CRM use case is exactly where Capacities's typed objects pay for themselves. Think notes on 80 people you stay in touch with, with object types for "contact," "company," and "interaction." The links between objects are the value. The AI answering layer is secondary. Atlas is built for research corpora and would feel awkward stretched over a CRM workflow.
Podcast and book tracking is another Capacities sweet spot. You want fields for rating, status, recommender, and themes. You want a query for "all unread books from people I met this year." You also want the daily note to surface those queries as you write. Atlas's project-and-source model has no good answer for this. It is built for "I have 80 PDFs and need to defend a thesis sentence," not for "I want to track my media with structure."
Capacities is a strong general PKM tool with daily notes and typed objects. Atlas is a research corpus tool with Knowledge Maps and source proof. For the jobs Capacities does well, Atlas is not a better Capacities. It is a different category of tool.
Common objections and edge cases
"I already have hundreds of typed objects in Capacities. Will I lose all that structure if I switch?" The typed structure does not migrate as a first-class concept, because Atlas does not have typed objects. What you keep is the source PDFs and the markdown content of your notes. What you lose is the schema and the saved queries. The practical path is to keep Capacities for the structured PKM you have built. Use Atlas beside it for the literature-heavy work where maps and source proof earn their keep. The two workflows coexist cleanly. Sources must be uploaded to each tool separately, but that is a small overhead for most research setups.
"My research is short bursts of 10 to 20 sources, not multi-month projects. Does the compounding graph matter?" Probably not, and we will say so. The compounding graph is the wedge for sustained, multi-month work where the same corpus shows up across projects. For self-contained 10-to-20-source bursts, the Knowledge Map and claim-source-justification still earn their keep, but the compounding graph is mostly idle. If short-burst, self-contained research is all you do, Capacities's session-isolated form fits the workflow better and the upgrade case for Atlas is weaker.
"What about privacy and where my papers are stored?" Atlas runs on cloud infrastructure. Your uploaded papers and chats are private to your account and are not used to train Atlas's models. If you need local-only storage, that is a real trade-off. Capacities is closer to that constraint. The decision is the same one you make for any cloud tool. Read the privacy policy. Run it past your data reviewer. Then decide whether the feature gain justifies the cloud posture.
Synthesize your research corpus with cited answers in Atlas
Use Atlas when Capacities holds your PKM substrate but your research sources need claim-source reasoning traces, not just linked object properties
Frequently Asked Questions
Yes. That is the core of Atlas's citation surface. Every answer is rendered as a claim-source-justification triple: the claim, the passage it draws from, and a one-sentence explanation of why the passage supports the claim. You can click into the source paragraph and read the highlighted sentences in context. Capacities may cite at the sentence level or link to sources, but it does not render the reasoning trace that connects the claim to the passage. That trace is the move when you need to defend a thesis sentence, a brief paragraph, or a treatment-plan summary. Read more about how Atlas grounds claims in Verifiable AI Research (2026): What It Actually Means.