Atlas vs Mem (2026): An In-Depth Research Comparison
Atlas is a visual research workspace; Mem is an AI-first note-taking tool with auto-organising notes. Compare on paper deconstruction, citation grounding.
- Byline

Summary
Use Atlas for citation-grounded research synthesis. Use Mem for AI-assisted personal notes and auto-organized capture.
The updated comparison covers citation grounding, Knowledge Maps, markdown migration, auto-organization, and compounding context.
Atlas traces claims to source passages, while Mem focuses on finding and organizing personal notes.
Mem can remain useful for lightweight capture while Atlas handles research corpora that need verifiable answers.

Build a cited Knowledge Map from your sources
Use Atlas when you need AI answers grounded in specific uploaded sources with traceable evidence—not just AI that connects your personal notes
Note: We make Atlas. This is a comparison written by the team that built it, not a neutral third-party review. Where Mem has the better answer for a given research job, the article says so plainly. See the table rows where Mem wins and the "When to choose Mem" section below. The goal is to give you the data you need to choose the right tool for the kind of work in front of you, not to convince you Atlas is the answer to every research job.
Atlas is a visual research workspace for people who need to understand a body of papers. That work might be a thesis, a treatment decision, a buying brief, or a literature review. Mem is an AI-first note app. It can auto-tag notes, answer questions over your notes with Ask Mem, and capture ideas from mobile or email.
The split is what happens after the first answer. Atlas turns each paper into a Knowledge Map, which is a visual map of the paper's argument. It turns a whole project into a Semantic Map. It also runs answers through claim-source-justification, so each claim points to a source passage and explains why that passage supports it. Over time, the work compounds into a project graph that gets more useful as you add sources.
Mem is strong at personal capture. Its auto-tags, Ask Mem chat, and mobile flow are useful when your notes are the source of truth. Atlas earns the comparison when the answer must be trusted, checked, and reused.
The technical boundary is simple. Mem is built for fast notes and AI recall. Atlas is built for source-backed research projects. It is a managed cloud workspace, not a self-hosted memory API. If you are testing agent memory systems, Mem0-like tools are the closer match. If you need to trace an answer to a paper paragraph, Atlas is the relevant comparison.
How we compared Atlas and Mem
We compared the tools by the job the user is trying to finish. Atlas was scored on source upload, paper maps, cited answers, project maps, and reuse across a research corpus. Mem was scored on note capture, auto-organization, Ask Mem recall, mobile capture, and personal-note workflow. The key question is whether the work starts from external sources that must be cited or from personal notes that must be easy to find later.
Feature Comparison Matrix
| Atlas | Mem |
|---|---|
| Citation grounding: claim, source passage, and justification shown together. Atlas wins for defensible research synthesis. | Ask Mem can search notes, but it does not make claim-level justification the core surface. |
| Knowledge Maps: deconstructs uploaded papers into claims, evidence, definitions, and relations. Atlas wins for research recall. | Auto-organizes personal notes and tags. Mem wins for low-friction capture. |
| Source upload: built around papers, markdown, and project sources that need cited answers. | Built around mems, daily notes, meetings, and personal capture. |
| Project memory: citations, mentions, Knowledge Maps, and Semantic Maps compound across projects. | Per-account note graph helps personal recall. |
| Low-friction personal capture: ✗ Atlas asks you to choose a project first. | Mem ✓ auto-tags notes and keeps capture lighter. |
| Pricing: evaluation sample, then Atlas Pro at $20/mo or $204/yr. | Mem is lower-cost for personal notes at $10/mo or $99/yr. |
Table 1: The table is the proof surface for the comparison. It shows why Atlas is stronger when the output must cite sources, and why Mem is stronger when the job is capture and recall.
Interface snapshots
How is Atlas different?
Mem and Atlas overlap on reading, notes, and AI answers. They split on three jobs that decide whether the output can be checked by someone else.
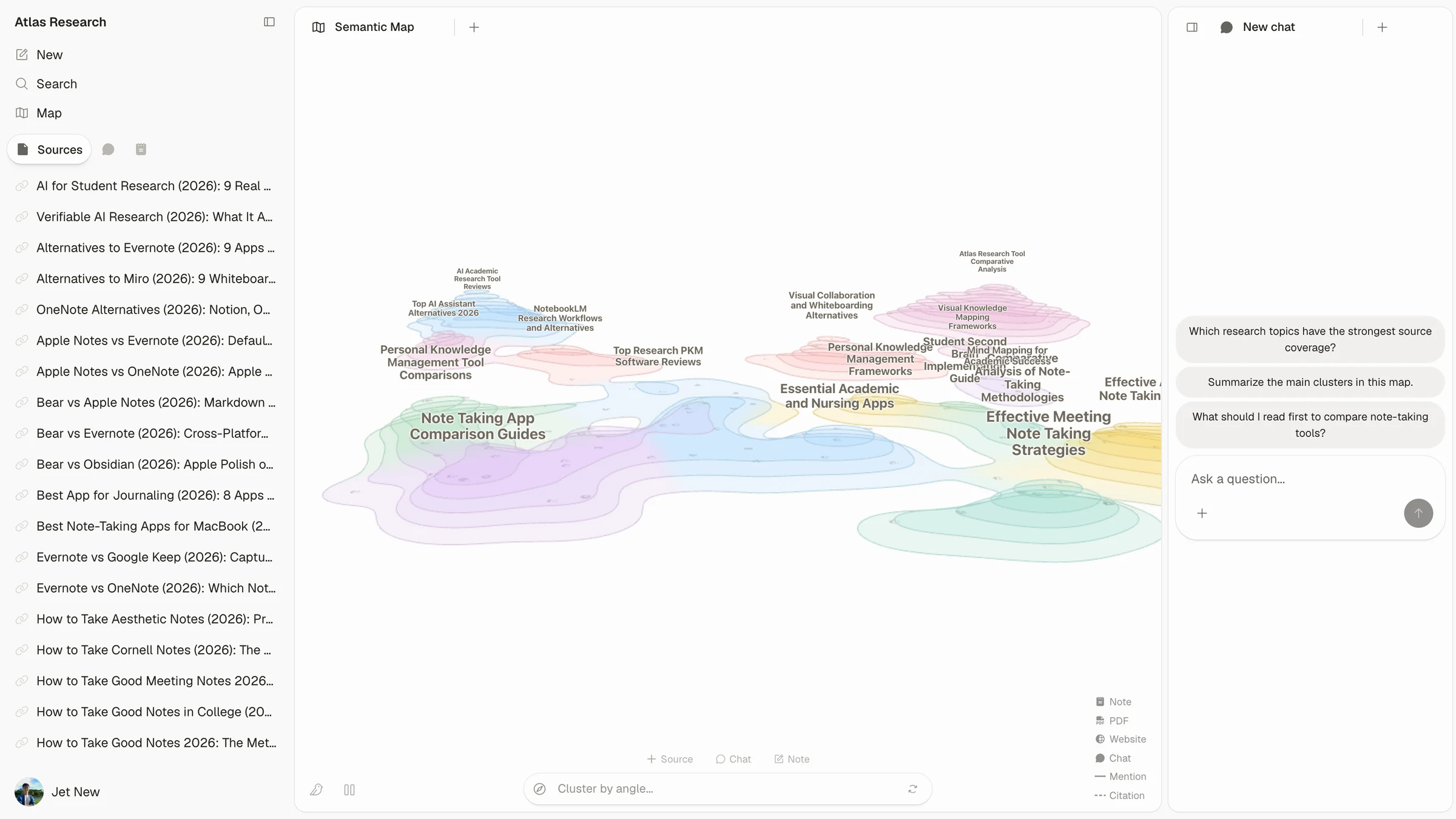
1. Visual maps of every paper and project
Atlas builds two visual maps as you read. A Knowledge Map breaks one paper into claims, evidence, definitions, and links between them. You see the paper's spine first. Then you can open the supporting passage with a click.
A Semantic Map works at the project level. It places sources, notes, chats, and citations on a visual canvas. Related items cluster by topic. You can view the same project from a new angle without re-reading the folder.
"It's like an ultimate GPT. I can finally see what I've read." Kyle Lao, CEO & Co-founder of MenSC Labs
Mem does not break each paper into a claim-and-evidence map. It also does not re-map an entire project by topic angle. If you have tried to recover a paper's structure weeks later, the Knowledge Map is the first Atlas surface that helps. Visual maps make a body of papers legible at a glance.
2. Every claim traces to a source, and Atlas explains why the source supports it
The hard problem is not only made-up text. It is a claim with a citation that does not support it. Atlas answers with a claim-source-justification triple: the claim, the source passage, and a short reason the passage supports the claim. You can open the source paragraph and read the highlighted text.
Atlas measures this with the H/V ratio. It checks how often a cited sentence fails a passage-level review. Atlas targets H/V < 0.1, and we explain the method in Verifiable AI Research (2026): What It Actually Means.
Mem answers may cite or link to sources. The difference is that Mem does not make the claim-level proof trace the main surface. For casual questions, that gap may not matter. For a thesis, brief, or treatment summary, it does. Every claim traces to its source, and Atlas explains why the source justifies it.
3. Your projects compound: the second month is 10× the first
Mem treats each workspace as a cleaner container. Work goes in, an answer comes out, and the next project can start fresh. Atlas keeps a persistent knowledge graph across projects. Citations, mentions, Knowledge Maps, and Semantic Maps become graph layers that later chats can use.
Open a related project months later and Atlas can surface prior sources, notes, and chats. Long-term users describe this as "the second month is 10× the first" because the graph has material to work with. John Tan, a postdoc using Atlas for a multi-year review, put it this way: "the only tool where the work I did last semester is still doing work for me this semester." Projects get smarter the longer you use Atlas.
Architecture and retrieval differences
The architecture matters because "AI memory" can mean different products. Mem is built around personal notes. It favors fast capture and recall over notes you already wrote.
Atlas is built around a research corpus. Uploaded sources become structured project objects. Citations and mentions become graph links. Answers must point back to passages that can support them.
That design is slower to explain than "ask your notes." It is also why Atlas fits literature reviews, thesis work, and research briefs. Atlas is not a self-hosted memory layer or a developer API for agent frameworks. If that is your test, Mem0-like systems may be the closer comparison.
How Mem0, Zep, and LangMem fit
Mem0, Zep, and LangMem belong in a different branch of this decision. They are memory layers for AI agents and applications, not personal note apps. Mem0 describes itself as memory infrastructure for agents and apps with persistent context. Zep focuses on enterprise agent memory served through context graphs. LangMem is a LangChain project for extracting useful information from interactions, refining agent behavior, and maintaining long-term memory.
Use those tools when you are building an agent that needs to remember users, preferences, or prior conversations across sessions. Use Mem when you want a personal notes workspace with capture and recall. Use Atlas when the input is a research corpus and the output needs claim-level citations. That separation matters because "AI memory" in a developer stack is not the same job as source-grounded synthesis from papers.
Comparing Atlas and Mem: feature comparison
Both tools touch a researcher's day, but they solve different jobs. Atlas covers paper maps, project maps, cited AI answers, and reuse across a research corpus. Mem covers personal notes, auto-tags, and chat over the note graph.
Mem is broader for personal note capture. Atlas is deeper when the citation has to hold up. The next sections compare paper maps, project maps, cited answers, source annotations, and long-running project memory. Each table includes at least one row where Mem wins or ties.
If the source-backed side of the comparison matches your work, upload one research source to Atlas and generate a cited Knowledge Map. The evaluation sample is enough to test whether Atlas's citation trace is worth adding beside Mem.
Paper deconstruction (Knowledge Map)
The Knowledge Map is Atlas's per-paper view. It breaks one paper into claims, evidence, definitions, and links between them. The node text comes from the paper, not from a loose summary. Breadcrumbs let you move from the paper's main claim to a specific paragraph.
| Atlas | Mem |
|---|---|
| Multi-level argument structure ✓ | Auto-tagged notes from PDF content |
| Labeled relations (motivates, causes, enables) ✓ | ✗ |
| Faithful-to-source node text ✓ | ✗ |
| Hierarchical breadcrumbs ✓ | ✗ |
| ✗ | Auto-organising notes with AI tagging ✓. tagging, not citation grounding |
Good to know: The bottom row belongs to Mem. Atlas does not ship that surface. The Knowledge Map's payoff is recovering a paper's argument three weeks after you first read it, when topic chips alone are no longer enough.
Project / corpus view (Semantic Map)
The Semantic Map is Atlas's project view. It places sources, notes, chats, and citations on a canvas. Related items cluster by topic. You can view the same project from a new angle without uploading the sources again.
| Atlas | Mem |
|---|---|
| Spatial embedding of sources + notes + chats ✓ | Auto-clustered note collections |
| Auto-labeled topic clusters ✓ | ✗ |
| Topic-angle re-projection ✓ | ✗ |
| Cross-project view ✓ | ✗ |
| ✗ | Ask Mem chat over personal notes ✓. personal-notes scope, not papers |
Good to know: Mem's strength on that row is genuine. If your work depends on it, that's the boundary. The Semantic Map's payoff is when 200 papers stop being a folder and start being a corpus you can re-project under different topic angles without re-reading.
Citation-grounded answers
Atlas produces claim-source-justification triples. Each answer shows the claim, the passage, and a short reason the passage supports the claim. You can jump to the source paragraph, read the highlighted sentences, and check whether the reasoning holds.
| Atlas | Mem |
|---|---|
| Claim-source-justification triples ✓ | Ask Mem AI chat (no claim-source-justification) |
| Reasoning traces (why this passage supports this claim) ✓ | ✗ |
| Jump-to-source with passage highlight ✓ | ✗ |
| H/V ratio < 0.1 benchmark published ✓ | ✗ |
| ✗ | Fast mobile capture and email-to-Mem ✓. capture surface, not reasoning |
Good to know: Both tools have a citation surface. The wedge is whether the surface explains why a passage justifies a claim, not just which passage was cited. For everyday Q&A the gap is invisible, but for a thesis sentence or a brief paragraph it's the whole game.
Literature-grounded annotations
Atlas annotates each paper when you upload it. Citations inside the paper become objects you can inspect. When the cited source is open access, Atlas can pull the relevant passage. That shows how one paper builds its argument from other sources.
| Atlas | Mem |
|---|---|
| Auto-annotate on ingest ✓ | ✗ |
| Multi-citation synthesis (how citations build the argument) ✓ | ✗ |
| Resolve cited sources (open-access) ✓ | ✗ |
| Exact passage / page / paragraph anchors ✓ | ✗ |
| ✗ | AI-driven auto-tagging on capture ✓. tagging, not deconstruction |
Good to know: Literature-Grounded Annotations resolve citations inside the paper you're reading. When a paper cites an open-access source, Atlas pulls in the cited passage. This is not broad web grounding. It is a way to inspect how one paper uses its cited sources.
Compounding context across projects
Atlas builds a four-layer graph across projects. Citations, mentions, Knowledge Maps, and Semantic Maps become context for later chats.
| Atlas | Mem |
|---|---|
| Persistent per-user knowledge graph ✓ | Per-account note graph |
| Citations + mentions + KMs + SMs accumulate ✓ | ✗ |
| Chat history reusable across projects ✓ | ✗ |
| Cross-project source reuse ✓ | ✗ |
| ✗ | Mobile-first interface design ✓. platform focus, not capability |
Good to know: Compounding is hard to show in a short demo. It matters more in week eight. If your work is many small, unrelated projects, Mem's cleaner separation is the right choice. Atlas pays off when research runs for months.
Price comparison
Atlas is a paid product. There is no permanent free plan. The evaluation sample includes 10 sources and 5 lifetime AI chats. After that, Atlas Pro is $20/mo or $204/yr. At that tier, Atlas includes Knowledge Map, Semantic Map, claim-source-justification, and the project graph.
| Atlas | Mem |
|---|---|
| Free: ✗ (evaluation sample only: 10 sources · 5 lifetime AI chats) | Free: Limited free trial ✓ |
| Pro: $20/mo or $204/yr (1,000 sources · 1,000 chats/month · all features) | Paid: Mem $10/mo or $99/yr, full AI features |
| Pro unlocks Knowledge Map, Semantic Map, claim-source-justification, compounding graph ✓ | ✗ |
When to choose Atlas vs Mem
- Want paper structure deconstructed multi-level? Go with Atlas. (Knowledge Map)
- Want answers that explain how each citation justifies the claim? Go with Atlas. (claim-source-justification)
- Want your projects to compound over months? Go with Atlas. (4-layer graph)
- Want auto-tags for personal notes and mobile capture? Go with Mem AI.
- Tied: capturing loose notes that need to be found later. Both work, with Mem designed for personal note capture. The split opens when you build a corpus you will return to.
Recommendations by user type
- PhD researchers: Atlas. Years 1-2 need paper maps for the literature review. Years 3-4 need cited claims for the thesis. Mem still works for one-off notes.
- Students doing literature reviews and thesis research: Atlas for the research project. The Knowledge Map saves time while reading. The project graph keeps prior work available next semester.
- Knowledge workers: Atlas when reading and citing sources is the core work. Mem when daily note capture is the main job.
- Personal researchers with high stakes: Atlas for medical, legal, major-purchase, or deep self-study projects. Mem is a fine starting point. Atlas helps once you need to defend the answer.
Mem is useful when the source of truth is your own stream of notes and the system's job is to resurface them with minimal filing. Atlas is useful when the source of truth is an external corpus that must be read, mapped, and cited. If the work starts as capture, Mem has less friction. If the work starts as evidence, Atlas gives the project a sturdier research structure.
Migrating from Mem to Atlas
Moving from Mem to Atlas is a content move, not a perfect feature port. Mem is built around the mem, which is a single note that can join an AI-organized note set. Ask Mem, Smart Write, Smart Templates, related notes, and auto-tags all sit on top of that object.
Atlas is built around the source. A source is often a PDF, but it can also be markdown or pasted text. Sources live inside a project. On upload, Atlas maps them, adds them to the Semantic Map, and makes them available to cited chat.
The clean migration path is the note body. Mem exports notes as markdown, and Atlas accepts markdown as a source. Upload the markdown file, or paste it into a new Atlas source. If an Ask Mem answer is worth keeping, copy the answer into a markdown note first. The answer text moves. The live Mem chat thread does not.
Some objects do not migrate cleanly. Mem's auto-tags become plain text or metadata. Smart Templates stay in Mem if you rely on them. The related-notes graph also stays in Mem. For any source PDFs behind those notes, upload the PDFs directly to Atlas. The note prose is the migration target. The PDF is the upgrade target.
A worked example: literature-review section from 8 papers
Say you have eight PDFs on one literature review topic, such as memory consolidation during sleep. You need a 600-word section. Each claim needs a passage-level citation so your advisor can check it.
The Mem workflow starts with Ask Mem over your notes. You import the papers or paste key passages into eight mems. Mem auto-tags them under the topic. Then you ask, "what do these papers say about replay during slow-wave sleep?" Mem returns an answer drawn from your notes. You copy useful paragraphs into Smart Write and edit from there. For a quick first draft, that is fast.
The Atlas workflow starts with the PDFs. You create a project called "Sleep consolidation" and upload the eight papers. Each paper becomes a Knowledge Map with claims, evidence, definitions, and links drawn from the paper. You can scan those maps and recover the shape of each argument without re-reading.
Then you open the Semantic Map. The eight papers appear as clusters on a canvas. You can view them under a new angle, such as hippocampal versus neocortical replay, without uploading them again.
Finally, you ask the synthesis question in project chat. Atlas returns claim-source-justification triples. For each thesis sentence, you get the source passage and a short reason it supports the claim. Click the claim, read the source paragraph, and accept or replace the citation.
The output difference is the review burden. Mem gives you a useful draft that still needs manual source checking. Atlas gives you a draft with each sentence already tied to a passage. The verification pass becomes checking the links, not re-reading all eight PDFs.
When Mem is the right call
Mem is the better tool for several jobs Atlas does not target.
Choose Mem for daily or weekly journaling with AI recall. Ask Mem can resurface notes you wrote months ago. Atlas is not a journal, and it does not optimize for date-keyed personal recall.
Choose Mem for fast capture with auto-tags. If choosing a folder is the bottleneck, Mem's auto-tagging helps. Atlas asks you to choose a project, which is useful for research but awkward for loose personal notes.
Choose Mem for a free-form AI scratchpad that mixes meeting notes, ideas, and references. Atlas keeps project boundaries stricter. That is useful for source work, but it costs you in casual capture.
Choose Mem if you need a desktop plus mobile journal with offline capture. Atlas is a cloud-first web product with strong desktop browser support and lighter mobile capture. The common thread is simple: Mem is for personal note organization. Atlas is for research where citation-grounding is the deliverable.
Common objections and edge cases
"I already have 2,000 mems. Do I really export all of them?" No. Most users migrate only the subset that maps to a research corpus they are actively building. The 2,000-mem personal stream stays in Mem (that is where it belongs), and the 30-80 mems that are research synthesis on a specific topic get exported as markdown and uploaded to the relevant Atlas project. The cleanest pattern we hear from users running both tools is: Mem stays the personal-note layer, Atlas becomes the research-corpus layer, and there is no expectation that the two graphs sync. The mental cost of the dual-tool stack is lower than the cost of forcing either tool to do the other tool's job.
"What about the Mem AI chats I have already had: can Atlas re-run them?" Atlas cannot import a Mem chat thread as a live, re-runnable conversation, because the chats are bound to Mem's note-graph context, which Atlas does not replicate. The practical move is to copy the chat output that was actually useful into a markdown note and upload that note (or the underlying PDFs) to Atlas. If the answer was right, the answer text is now an Atlas source, and if you need to re-derive it from primary sources, Atlas's claim-source-justification chat over the uploaded PDFs is the upgrade path.
"I write more than I read. Does any of this apply to me?" Less than the article assumes. If your work is mostly authored prose with light reference to sources, Mem's Smart Write plus Ask Mem covers the writing surface and Atlas is overkill. The threshold where Atlas earns the comparison is when the reading and citing of sources is on the critical path of what you ship (a thesis, a brief, a treatment plan, a teardown), not when writing volume is the bottleneck. Use the tool whose primitive matches the bottleneck of your work.
Build a cited Knowledge Map from your sources
Use Atlas when you need AI answers grounded in specific uploaded sources with traceable evidence—not just AI that connects your personal notes
Frequently Asked Questions
Yes. That is the core of Atlas's citation surface. Every answer is rendered as a claim-source-justification triple: the claim, the passage it draws from, and a one-sentence explanation of why the passage supports the claim. You can click into the source paragraph and read the highlighted sentences in context. Mem may cite at the sentence level or link to sources, but it does not render the reasoning trace that connects the claim to the passage. That trace is the move when you need to defend a thesis sentence, a brief paragraph, or a treatment-plan summary. Read more about how Atlas grounds claims in Verifiable AI Research (2026): What It Actually Means.